-
[2월 3주차-2/20(1)]다나와 무선청소기 데이터 분석 및 시각화 🧹📊Why Not SW CAMP 5기/수업 기록 2025. 2. 20. 12:23
1. 데이터 전처리 🛠️
1.1 데이터 불러오기 및 기본 정보 확인 📂
import pandas as pd data = pd.read_excel("files/danawa_crawling_result.xlsx") data.info()300개의 데이터가 있으며, 상품명, 스펙 목록, 가격 등의 컬럼이 존재합니다.
1.2 상품명 분리 (회사명과 제품명) 🏭📦
company_list = [] product_list = [] for title in data['상품명']: title_info = title.split(' ', 1) company_list.append(title_info[0]) product_list.append(title_info[1])상품명을 회사명과 제품명으로 분리하여 각각 리스트에 저장합니다.
1.3 스펙 목록에서 필요한 요소 추출 (카테고리, 사용시간, 흡입력) 🔍
category_list = [] use_time_list = [] suction_list = [] for spec_data in data['스펙 목록']: spec_list = spec_data.split(' / ') category_list.append(spec_list[0]) use_time_value = None suction_value = None for spec in spec_list: if '사용시간' in spec: use_time_value = spec.split()[1].strip() elif '흡입력' in spec: suction_value = spec.split()[1].strip() use_time_list.append(use_time_value) suction_list.append(suction_value)1.4 사용시간 단위 통일 (분 단위 변환) ⏳
def convert_time_minute(time): try: if '시간' in time: hour = time.split('시간')[0] minute = time.split('시간')[-1].split('분')[0] if '분' in time else 0 else: hour = 0 minute = time.split('분')[0] return int(hour) * 60 + int(minute) except: return None new_use_time_list = [convert_time_minute(time) for time in use_time_list]1.5 흡입력 단위 통일 (AW 기준 변환) 💨
def get_suction(value): try: value = value.upper() if 'AW' in value or 'W' in value: return int(value.replace('A','').replace('W','').replace(',','')) elif 'PA' in value: return int(value.replace(',','')) / 100 else: return None except: return None new_suction_list = [get_suction(power) for power in suction_list]1.6 전처리 완료 및 데이터 저장 ✅
pd_data = pd.DataFrame({ '카테고리': category_list, '회사명': company_list, '제품': product_list, '가격': data['가격'], '사용시간': new_use_time_list, '흡입력': new_suction_list }) # 핸디/스틱청소기만 선택하여 저장 pd_data_final = pd_data[pd_data['카테고리'].isin(['핸디/스틱청소기'])] pd_data_final.to_excel("files/danawa_data_final.xlsx", index=False)
2. 데이터 시각화 📈
2.1 가성비 좋은 제품 탐색 🔎💰
price_mean_value = danawa_data['가격'].mean() suction_mean_value = danawa_data['흡입력'].mean() use_time_mean_value = danawa_data['사용시간'].mean() condition_data = danawa_data[ (danawa_data['가격'] <= price_mean_value) & (danawa_data['흡입력'] >= suction_mean_value) & (danawa_data['사용시간'] >= use_time_mean_value) ]2.2 한글 폰트 설정 🖋️
import matplotlib.pyplot as plt import seaborn as sns from matplotlib import font_manager, rc import platform if platform.system() == 'Darwin': rc('font', family='AppleGothic') elif platform.system() == 'Windows': path = 'c:/Windows/Fonts/malgun.ttf' font_name = font_manager.FontProperties(fname=path).get_name() rc('font', family=font_name) else: print("sorry")2.3 청소기 가성비 시각화 🎨
chart_data = danawa_data.dropna() suction_max_value = danawa_data['흡입력'].max() use_time_max_value = danawa_data['사용시간'].max() plt.figure(figsize=(20,10)) plt.suptitle('무선 청소기', fontsize=15) plt.title('성능', fontsize=11) sns.scatterplot(x='흡입력', y='사용시간', size='가격', hue=chart_data['회사명'], data=chart_data, sizes=(10, 1000)) plt.plot([0, suction_max_value], [use_time_mean_value, use_time_mean_value], lw=1) plt.plot([suction_mean_value, suction_mean_value], [0, use_time_max_value], 'r--', lw=1) plt.xlabel('흡입력', fontsize=14) plt.ylabel('사용시간', fontsize=14) plt.legend() plt.show()
2.4 인기 제품의 데이터 시각화🎨
chart_data_selected = chart_data[:20] plt.figure(figsize=(20,10)) plt.title('무선 청소기 TOP 20', fontsize=11) sns.scatterplot(x='흡입력', y = '사용시간', size = '가격', hue = chart_data_selected['회사명'], data = chart_data_selected, sizes = (100, 2000), ) # 사용 시간 평균을 선으로 plt.plot([60, suction_max_value], [use_time_mean_value, use_time_mean_value], lw = 1) # 흡입력 평균을 선으로 plt.plot([sucton_mean_value, sucton_mean_value], [20, use_time_max_value], 'r--', lw = 1) for index, row in chart_data_selected.iterrows(): x = row['흡입력'] y = row['사용시간'] s = row['제품']. split()[0] plt.text(x, y, s, size=20) plt.xlabel('흡입력',fontsize=14) plt.ylabel('사용시간', fontsize=14) plt.legend() plt.show()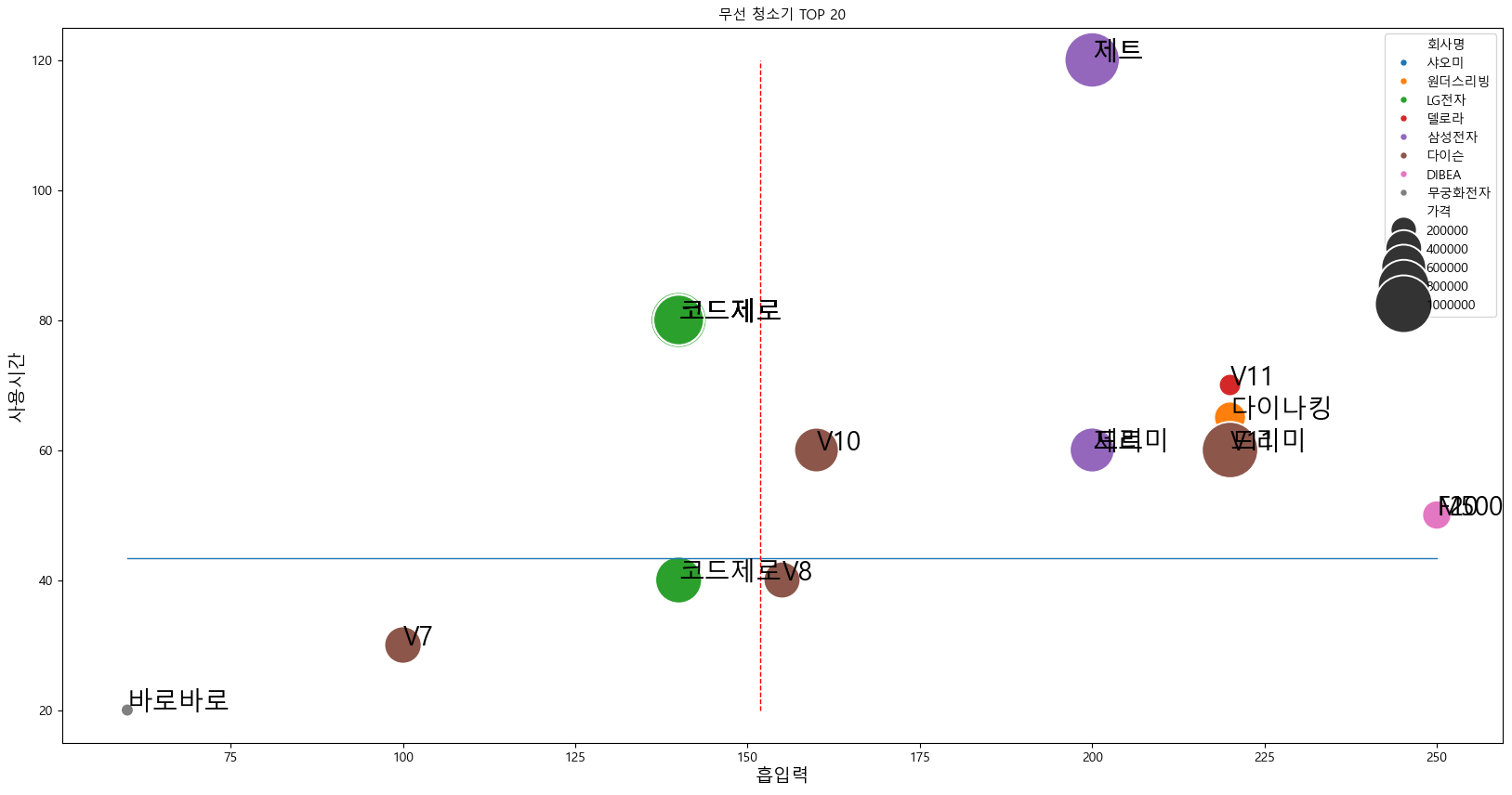
3. 결론 🏁
이번 분석을 통해 다나와에서 크롤링한 무선 청소기 데이터를 전처리하고, 사용시간과 흡입력 기준으로 성능(가성비)을 분석해보았습니다. 특히 가성비 좋은 제품을 찾고, 브랜드별 성능을 비교할 수 있도록 시각화했습니다.! 🚀🧼
'Why Not SW CAMP 5기 > 수업 기록' 카테고리의 다른 글
[2월 3주차-2/20(3)]대한민국 행복 지도 데이터 분석 (0) 2025.02.20 [2월 3주차-2/20(2)]미세먼지와 날씨 데이터 분석 및 시각화 (0) 2025.02.20 [2월 3주차-2/19]왜 우리 동네에는 스타벅스가 없을까? (0) 2025.02.20 [2월 3주차-2/18(4)]📊 월별 외국인 관광객 데이터 전처리 및 통합 분석 (0) 2025.02.19 [2월 3주차-2/18(3)]📊 YouTube 채널 랭킹 크롤링 및 데이터 분석 (0) 2025.02.18