-
[3월 2주차-3/12(2)]머신러닝 개념 총정리 - 지도학습, 선형 회귀, 로지스틱 회귀Why Not SW CAMP 5기/수업 기록 2025. 3. 12. 15:12
1. 머신러닝이란?
머신러닝은 데이터가 주어지면, 기계가 스스로 데이터로부터 규칙성을 찾는 것에 집중하는 학문입니다. 머신러닝의 주요 학습 방식은 다음과 같이 세 가지로 나뉩니다.
🔹 머신러닝의 학습 방식
- 지도학습(Supervised Learning)
- 정답(레이블)이 있는 데이터를 학습하여 예측 모델을 생성합니다.
- 예제: 분류(Classification), 회귀(Regression)
- 비지도학습(Unsupervised Learning)
- 정답(레이블) 없이 패턴을 찾아내는 방법입니다.
- 예제: 군집화(Clustering), 변환(Transform), 연관규칙(Association)
- 강화학습(Reinforcement Learning)
- 보상을 기반으로 최적의 행동을 학습하는 방법입니다.
- 예제: 알파고, 자율 주행
🔹 머신러닝 데이터셋 분할
모델 학습 시 데이터는 훈련 데이터, 검증 데이터, 테스트 데이터 세 가지로 나뉘어야 합니다.
- 훈련 데이터(Train Set): 모델을 학습시키는 데 사용
- 검증 데이터(Validation Set): 학습 중 모델의 성능을 평가
- 테스트 데이터(Test Set): 학습 완료 후 모델의 최종 성능을 평가
일반적인 데이터 분할 비율: 훈련(60%) - 검증(20%) - 테스트(20%)
🔹 딥러닝 모델의 일반적인 학습 과정
- 데이터를 훈련/검증/테스트 데이터로 나눔 (예: 6:2:2 비율)
- 훈련 데이터로 모델 학습 진행 (Epoch +1)
- 검증 데이터로 모델을 평가하고 정확도 및 오차를 계산
- 검증 데이터의 오차가 증가하면 과적합(Overfitting) 징후이므로 학습을 중단
- 학습 종료 후 테스트 데이터로 최종 평가 수행
2. 선형 회귀(Linear Regression)
선형 회귀는 독립 변수(x)와 종속 변수(y) 간의 선형 관계를 모델링하는 기법입니다.
🔹 단순 선형 회귀(Simple Linear Regression)
- 수식: y=wx+by = wx + b
- w(weight): 가중치 (기울기)
- b(bias): 편향 (y절편)
🔹 다중 선형 회귀(Multiple Linear Regression)
- 여러 개의 독립 변수를 포함하는 회귀 분석
- 수식: y=w1x1+w2x2+...+wnxn+b
🔹 비용 함수(Cost Function): 평균 제곱 오차(MSE)
모델이 얼마나 잘 맞는지를 평가하기 위해 오차를 측정하는 함수입니다.
- 평균 제곱 오차(Mean Squared Error, MSE)
- 오차가 작을수록 모델이 더 정확함을 의미합니다.
🔹 옵티마이저: 경사 하강법(Gradient Descent)
- 옵티마이저: 비용 함수(MSE)의 값을 최소화하기 위해 사용되는 최적화 알고리즘
- 가장 기본적인 옵티마이저 알고리즘: 경사하강법
- 기울기(Gradient)를 기반으로 가중치(W)와 편향(b)를 조정
🔹 정리
- 가설, 비용 함수 , 옵티마이저는 머신 러닝 분야에서 사용되는 포괄적 개념.
- 풀고자하는 각 문제에 따라 가설 , 비용 함수 , 옵티마이저는 전부 다를 수 있음.
- 선형회귀에 가장 적합한 비용 함수는 MSE, 옵티마이저는 경사하강법임.
3. 케라스로 구현하는 선형 회귀
1️⃣ Keras 모델 기본 형식
import tensorflow as tf from tensorflow import keras from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras import optimizers import numpy as np✅무엇을 하는 코드인가?
- Sequential() : 순차적으로 쌓이는 신경망 모델을 만들기 위한 객체.
- Dense() : 완전 연결(Dense) 계층, 즉 선형 회귀 레이어 추가.
- optimizers.SGD() : 경사하강법(SGD) 옵티마이저 설정.
- compile() : 모델 학습을 위한 설정 (손실 함수, 옵티마이저 등 지정).
- fit() : 실제 모델 학습 진행.
2️⃣ 데이터 준비
x = np.array([1,2,3,4,5,6,7,8,9]) # 공부 시간 y = np.array([11,22,33,44,53,66,77,87,95]) # 성적✅ 무엇을 하는 코드인가?
- x: 공부한 시간 (입력값)
- y: 시험 성적 (출력값)
- 입력(x)와 출력(y)을 학습 데이터로 사용!
3️⃣ 선형 회귀 모델 정의
model = Sequential() # 순차적 모델 생성 # 선형 회귀 레이어 추가 model.add(Dense(1, input_dim=1, activation='linear'))✅ 무엇을 하는 코드인가?
- Sequential() : Keras에서 모델을 생성하는 기본 방법.
- Dense(1, input_dim=1, activation='linear') :
- 1 : 출력 뉴런 개수 (선형 회귀라서 1개).
- input_dim=1 : 입력 뉴런 개수 (x의 차원이 1개).
- activation='linear' : 선형 활성화 함수 사용 (선형 회귀는 활성화 함수가 필요 없음).
4️⃣ 옵티마이저 설정 및 모델 컴파일
sgd = optimizers.SGD(learning_rate = 0.01) # SGD 경사하강법 사용 model.compile(optimizer=sgd, loss='mse', metrics=['mse'])✅ 무엇을 하는 코드인가?
- SGD(learning_rate=0.01) → 학습률 0.01인 확률적 경사하강법(SGD) 사용.
- loss='mse' → 평균 제곱 오차(MSE)를 손실 함수로 설정.
- metrics=['mse'] → 학습 과정에서 MSE를 출력.
5️⃣ 모델 학습 (Epoch 300)
model.fit(x, y, epochs=300)✅ 무엇을 하는 코드인가?
- fit() : 주어진 x, y 데이터를 바탕으로 모델을 학습.
- epochs=300 → 학습을 300번 반복하여 가중치(W)와 편향(b)을 최적화.
6️⃣ 모델 결과 시각화

import matplotlib.pyplot as plt plt.plot(x, model.predict(x), 'b', x, y, 'k.') # 예측값과 실제값 비교 plt.show()✅ 무엇을 하는 코드인가?
- model.predict(x) → 학습된 모델을 이용하여 x값에 대한 예측 수행.
- 'b' → 파란색 선(모델이 학습한 직선).
- 'k.' → 검은색 점(실제 데이터 포인트).
- plt.show() → 그래프 출력.
📌 결과 :
- 그래프를 보면 학습된 선형 회귀 모델이 데이터와 얼마나 잘 맞는지 확인 가능!
7️⃣ 새로운 값 예측
print(model.predict(np.array([9.5]))) # [[102.2059]] print(model.predict(np.array([0.5]))) # [[6.3121185]]✅ 무엇을 하는 코드인가?
- x=9.5일 때 모델이 예측한 결과 출력 → y ≈ 102.2
- x=0.5일 때 모델이 예측한 결과 출력 → y ≈ 6.3
- 즉, 학습된 모델이 새로운 데이터에 대해 예측할 수 있도록 만든 것!
✅ 결론
- Sequential()을 사용해 모델을 만들고,
- Dense()를 사용해 선형 회귀 레이어를 추가.
- SGD(learning_rate=0.01)을 사용해 경사하강법을 적용.
- fit(x, y, epochs=300)을 통해 학습 진행.
- 학습된 모델을 그래프로 시각화하고, 새로운 데이터 예측도 수행.
4. 로지스틱 회귀(Logistic Regression)
로지스틱 회귀는 이진 분류(Binary Classification) 문제를 해결하는 기법입니다.
🔹 시그모이드 함수(Sigmoid Function)
로지스틱 회귀에서는 예측값을 0~1 사이의 확률 값으로 변환하기 위해 시그모이드 함수를 사용합니다.
🔹 케라스를 이용한 로지스틱 회귀 구현
import numpy as np import matplotlib.pyplot as plt from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras import optimizers x = np.array([-50, -40, -30, -20, -10, -5, 0, 5, 10, 20, 30, 40, 50]) y = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]) model = Sequential() model.add(Dense(1, input_dim=1, activation='sigmoid')) sgd = optimizers.SGD(learning_rate=0.01) model.compile(optimizer=sgd, loss='binary_crossentropy', metrics=['binary_accuracy']) model.fit(x, y, epochs=200) plt.plot(x, model.predict(x), 'b', x, y, 'k.') plt.show()🔹 모델 예측 결과
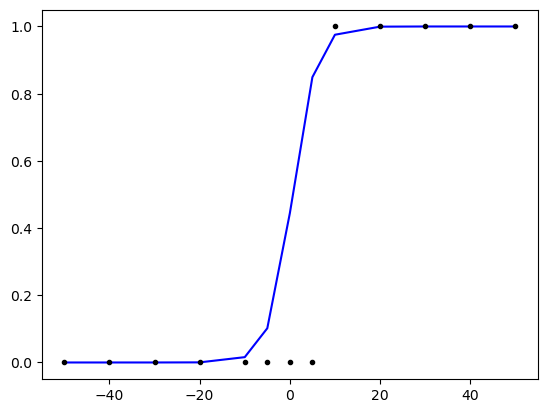
print(model.predict(np.array([1,2,3,4,4.5]))) # [[0.501], [0.557], [0.611], [0.662], [0.687]] print(model.predict(np.array([11,21,31,41,500]))) # [[0.9034601 ], [0.9886397 ], [0.9987658 ], [0.99986714], [1. ]]- 입력값이 10 이상이면 1에 가까운 값
- 입력값이 5 이하이면 0에 가까운 값 이여야 하는데
- 모델의 학습이 충분히 이루어지지 않았거나, 가중치(W)와 편향(b)의 초기값, 학습률이 적절하지 않기 때문에 0.5 이상의 값이 나옴
- epoch을 늘리고, 학습률을 줄이면 더 정확한 예측이 가능할 것.
5. 다중 로지스틱 회귀(Multiple Logistic Regression)
''' 독립 변수 2개 이상: 꽃받침의 길이와 꽃잎의 길이 종속 변수: 1개. 해당 꽃이 A인지 B인지 입력 차원=2 ''' import numpy as np import matplotlib.pyplot as plt from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras import optimizers import tensorflow as tf from tensorflow import keras X = np.array([[0,0],[0,1],[1,0],[0,2],[1,1],[2,0]]) y = np.array([0,0,0,1,1,1]) model = Sequential() model.add(Dense(1, input_dim=2, activation='sigmoid')) model.compile(optimizer = 'sgd', loss='binary_crossentropy', metrics=['binary_accuracy']) model.fit(X,y, epochs=2000) model.predict(X) ''' array([[0.17302638], [0.44414967], [0.46202478], [0.7531817 ], [0.76634693], [0.77901596]], '''6. 결론
- 머신러닝의 주요 학습 방식: 지도학습, 비지도학습, 강화학습
- 데이터 분할(훈련, 검증, 테스트)을 통해 과적합 방지
- 선형 회귀(Linear Regression): 회귀 문제 해결, MSE & SGD 사용
- 로지스틱 회귀(Logistic Regression): 이진 분류 문제 해결, 시그모이드 함수 사용
- TensorFlow Keras를 사용해 손쉽게 모델 구현 가능!
'Why Not SW CAMP 5기 > 수업 기록' 카테고리의 다른 글
[3월 2주차-3/13]딥러닝 기초 개념 정리 (0) 2025.03.13 [3월 2주차-3/12(3)]다중 클래스 분류 - 아이리스 품종 분류 (0) 2025.03.12 [3월 2주차-3/12(1)]코사인 유사도, 유클리드 거리, 자카드 유사도 - 차이점과 활용법 (0) 2025.03.12 [3월 2주차-3/11(4)]🏙️ 블로거들이 추천하는 서울 명소 분석하기! (WordCloud 시각화) (1) 2025.03.11 [3월 2주차-3/11(3)]🏆 카운트 기반의 단어 표현 (Bag of Words) (1) 2025.03.11 - 지도학습(Supervised Learning)